Technisches Whitepaper: IBM Db2 BLU Technologie für
den Mittelstand.
Ein kostenoptimierter Ansatz.

Folgt man der Installationsanweisung, ist eine der ersten Tätigkeiten das Setzen eines instanzweiten gültigen Parameters:
- db2set workload = analytics
Das hat zur Folge, dass alle Parameter für neue Datenbanken die Vorgaben nutzen, die für BLU gebraucht werden.
Insbesondere ist dann BLU beziehungsweise Spaltenorientierung die Vorgabe für neue Tabellen. Genau diese Vorgabe
sollte man umstellen, da in dem hier beschriebenen Szenario nur Datamart-Tabellen BLU und die Mehrzahl der Tabellen
klassisch zeilenorientiert angelegt werden. Außerdem sollte man bei einem gemischten Einsatz auf Auto-Maintenance
eher verzichten und dies zielgerichtet in den Skripten bzw. in die ETL-Prozesse einbauen.
- db2 update db cfg for %DBNAME using dft_table_org=row
- db2 update db cfg for %DBNMAE using AUTO_RUNSTATS=OFF
- db2 update db cfg for %DBNMAE using AUTO_REORG=OFF
Nun gilt es, einige Speicherbereiche sinnvoll zu setzen. Laut Empfehlung sind hier zwei Bereiche besonders speicherhungrig. Abhängig von der Anzahl der gleichzeitigen Zugriffe, gelten folgende Empfehlungen seitens IBM:
- Bis 20 concurrent User: 40% des verfügbaren Speichers fix dem Buffepool zuordnen, der zu den Tablespaces gehört, dem die BLU Tabellen zugeordnet sind. Bei mehr als 20 concurrent Usern sollten es immer noch 25% des gesamten Speichers sein.
- Bis 20 concurrent User: 40% des Speichers für den Sortheap reservieren (sheapthres_shr = 40% des Speichers, sortheap = 1/5 des Thresholds). Bei mehr als 20 concurrent User: 50% des Speichers für den sortheap reservieren (sheapthres = 50% des epcihers, sortheap = 1/20 des Thresholds)
- Trennung von BLU und Nicht-BLU in 2 Instanzen.
- Generell Befüllung der BLU-Tables initial über einen Bulk-Load bzw. am besten über Staging Tabellen und nachgelagerten load from cursor.
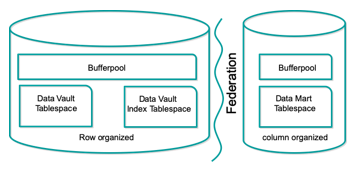
Diese Lösung erfordert tendenziell mehr CPUs und mehr Speicher. Dadurch gelangt man schnell an den Punkt, an dem
die Standard-Edition der Db2 nicht mehr ausreicht und zusätzliche Lizenzkosten entstehen. Zudem verdoppeln sich diverse Maintenance Aufwände, wie etwa im Bereich der Desaster-Recovery-Strategie etc.
Daher empfiehlt es sich folgende Kompromiss-Lösung:
- Bis 20 concurrent User: 30% des verfügbaren Speichers fix dem Buffepool zuordnen, der zu den Tablespaces
gehört, dem die BLU Tabellen zugeordnet sind. Bei mehr als 20 concurrent Usern sollten es immer noch 20% des
gesamten Speichers sein. - Bis 20 concurrent User: 40% des Speichers für den Sortheap reservieren (sheapthres_shr = 40% des Speichers,
sortheap = 1/5 des Thresholds). Bei mehr als 20 concurrent User: 50% des Speichers für den sortheap reservieren
(sheapthres = 50% des epcihers, sortheap = 1/20 des Thresholds) - Generell Befüllung der BLU-Tables initial über einen Bulk-Load bzw. am besten über Staging Tabellen und nachgelagerten load from cursor
- Keine Trennung der Instanzen
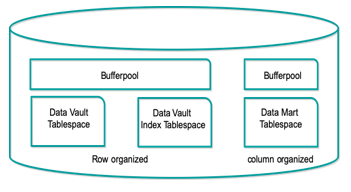
Bei der Datenbewirtschaftung ist darauf zu achten, dass die BLU-Tabellen insbesondere initial mit BULK-Loads befüllt
werden, damit die synapsis Tabelle zu Beginn einen sinnvollen Zustand hat. Außerdem sollte vermieden werden, bei
updates oder deletes auf die BLU Tabelle in der where Bedingung mehr als eine Spalte zu verwenden (im Idealfall nur
den primary key, der wiederrum nur eine Spalte enthalten sollte). Unter dieser Maßgabe kann nach dem initialen BULK Load mit insert else update / delete gearbeitet werden. Ansonsten, falls dies prozessual möglich ist, sollte mit einem
truncate und anschließendem BULK Load aus der Staging Tabelle fortfahren, um die BLU-Tabellen zu befüllen. Wichtig ist
zudem, dass alle Dimensionstabellen, die zu Faktentabellen hinzu gejoined werden sollen, auch BLU sind. Da Dimensionstabellen normalerweise nicht groß sind und es im Datamart keine foreign keys gibt, kann hier problemlos mit truncate
/ BULK-Load gearbeitet werden.
Das sieht dann schematisch folgendermaßen aus (hier ist im Core-Data Warehouse ein Data Vault verwendet. Das ist
optional):


Jörg Kremer
Head of Consulting
![]()
IBM Certified Database Administrator – Db2 11.1 LUW